Smart Chatbot Using NLTK and Keras
|Written by Rupam Goyal ,Piyush Malhotra, Aboli
In this Neural Network Project, we build a chatbot using deep learning methods. The chatbot will be trained in a database that contains categories (objectives), patterns and responses. We use a special recurrent neural network (LSTM) to distinguish the domain of a user’s message and provide a random response to a response list.
In this project we build a retrieval chatbot using NLTK, Keras, Python, etc.
1) What is Chatbot?
A chatbot is a smart piece of software that can communicate and perform human-like actions. Chatbots are widely used in customer communication, marketing on social networking sites and sending instant messages to the client. There are two basic types of discussion models depending on how they are constructed; Retrieval based and Generative based models.
a. Retrieval based Chatbots
Recovery dialogue uses pre-defined input patterns and responses. It then uses a certain type of selection method to select the correct answer. It is widely used in the industry to create goal-oriented conversations where we can customize the tone and flow of chatbot to drive our customers with a positive feeling.
b. Chatbots based on Generative
These models are not based on other previously defined responses.
They are based on seq 2 seq neural networks. It is the same concept as machine translation. In machine translation, we translate source code from one language to another language but here, we will convert input to output. Requires a large amount of data and is based on deep neural network.
2) Dataset Used
The dataset we use is ‘intents.json’. This is a JSON file that contains the patterns we need to find and the answers we want to get back to the user.

3) Prerequisites
Before reading the post, some concepts of Keras, good knowledge of Python, and Natural language processing (NLTK).Also the reader must be familiar with the basic Python syntax, data structures, Keras Library, working on Google Colab etc.
4) Model generation
For this project let us see the file structure and the type of files created:
- Intents.json — The data file which has predefined patterns and responses.
- train_chatbot.py — In this Python file, we wrote a script to build the model and train our chatbot.
- Words.pkl — This is a pickle file in which we store the words Python object that contains a list of our vocabulary.
- Classes.pkl — The classes pickle file contains the list of categories.
- Chatbot_model.h5 — This is the trained model that contains information about the model and has weights of the neurons.
- Chatgui.py — This is the Python script in which we implemented GUI for our chatbot. Users can easily interact with the bot.
For this project we have used Five steps to create a chatbot:

- Import and load the data file
First, create a filename like train_chatbot.py. We import the necessary packages for our chat and the variables are initialise that we will use in our Python project.
The data file is in JSON format so we used a json package to transfer the JSON file to Python.
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
import json
import pickle
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout
from keras.optimizers import SGD
import random
words=[]
classes = []
documents = []
ignore_words = ['?', '!']
data_file = open('intents.json').read()
intents = json.loads(data_file)2. Preprocess data
When working with text data, we need to do a variety of data preprocessing before developing machine learning or deep learning model. Depending on the needs we need to use a variety of functions to process data.
Tokenizing is the most basic and first thing you can do for text data. TTokenizing is the process of dividing the whole text into smaller parts like words.
We iterate through the patterns repeatedly and tokenize the sentence the nltk.word_tokenize () function and then add each word to the word list. We also create a list of our tag classes.
for intent in intents['intents']:
for pattern in intent['patterns']:
#tokenize each word
w = nltk.word_tokenize(pattern)
words.extend(w)
#add documents in the corpus
documents.append((w, intent['tag']))
# add to our classes list
if intent['tag'] not in classes:
classes.append(intent['tag'])We will now copy each word and remove duplicate words from the list. Lemmatizing is the process of converting a name into its lemma form and creating a pickle file to store Python objects that we will use while predicting.
# lemmatize, lower each word and remove duplicates
words = [lemmatizer.lemmatize(w.lower()) for w in words if w not in ignore_words]
words = sorted(list(set(words)))
# sort classes
classes = sorted(list(set(classes)))
# documents = combination between patterns and intents
print (len(documents), "documents")
# classes = intents
print (len(classes), "classes", classes)
# words = all words, vocabulary
print (len(words), "unique lemmatized words", words)
pickle.dump(words,open('words.pkl','wb'))
pickle.dump(classes,open('classes.pkl','wb'))3. Create training and testing data
Now, we will create training data where we will provide input and output. Our input will be a pattern and the output will be a class our input pattern belongs. But the computer does not understand the text so we convert the text to numbers.
# create our training data
training = []
# create an empty array for our output
output_empty = [0] * len(classes)
# training set, bag of words for each sentence
for doc in documents:
# initialize our bag of words
bag = []
# list of tokenized words for the pattern
pattern_words = doc[0]
# lemmatize each word - create base word, in attempt to represent related words
pattern_words = [lemmatizer.lemmatize(word.lower()) for word in pattern_words]
# create our bag of words array with 1, if word match found in current pattern
for w in words:
bag.append(1) if w in pattern_words else bag.append(0)
# output is a '0' for each tag and '1' for current tag (for each pattern)
output_row = list(output_empty)
output_row[classes.index(doc[1])] = 1
training.append([bag, output_row])
# shuffle our features and turn into np.array
random.shuffle(training)
training = np.array(training)
# create train and test lists. X - patterns, Y - intents
train_x = list(training[:,0])
train_y = list(training[:,1])
print("Training data created")4. Build the model
We have our training data ready, now we will build a deep neural network with 3 layers. We are using the Kera sequential API for this. After training the 200 times model, we obtained 95% accuracy in our model. Let’s save the model as ‘chatbot_model.h5’.
# Create model - 3 layers. First layer 128 neurons, second layer 64 neurons and 3rd output layer contains number of neurons
# equal to number of intents to predict output intent with softmax
model = Sequential()
model.add(Dense(128, input_shape=(len(train_x[0]),), activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(train_y[0]), activation='softmax'))
# Compile model. Stochastic gradient descent with Nesterov accelerated gradient gives good results for this model
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
#fitting and saving the model
hist = model.fit(np.array(train_x), np.array(train_y), epochs=200, batch_size=5, verbose=1)
model.save('chatbot_model.h5', hist)
print("model created")5. Predict the response
To predict the sentences and get a response from the user to let us create a new file ‘chatapp.py’.
We will download a trained model and use a graphical interface that will predict the response from the bot. The model will only tell us which class it is in, so we will use other functions that will identify the class and then find the random answer in the answer list.
We also import the required packages and upload the ‘words.pkl’ and ‘classes.pkl’ files created when we train our model:
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
import pickle
import numpy as np
from keras.models import load_model
model = load_model('chatbot_model.h5')
import json
import random
intents = json.loads(open('intents.json').read())
words = pickle.load(open('words.pkl','rb'))
classes = pickle.load(open('classes.pkl','rb'))To predict the class, we will need to provide input in the same way as we do while training. We will therefore create functions that will process the text and predict the class.
def clean_up_sentence(sentence):
# tokenize the pattern - split words into array
sentence_words = nltk.word_tokenize(sentence)
# stem each word - create short form for word
sentence_words = [lemmatizer.lemmatize(word.lower()) for word in sentence_words]
return sentence_words
# return bag of words array: 0 or 1 for each word in the bag that exists in the sentence
def bow(sentence, words, show_details=True):
# tokenize the pattern
sentence_words = clean_up_sentence(sentence)
# bag of words - matrix of N words, vocabulary matrix
bag = [0]*len(words)
for s in sentence_words:
for i,w in enumerate(words):
if w == s:
# assign 1 if current word is in the vocabulary position
bag[i] = 1
if show_details:
print ("found in bag: %s" % w)
return(np.array(bag))
def predict_class(sentence, model):
# filter out predictions below a threshold
p = bow(sentence, words,show_details=False)
res = model.predict(np.array([p]))[0]
ERROR_THRESHOLD = 0.25
results = [[i,r] for i,r in enumerate(res) if r>ERROR_THRESHOLD]
# sort by strength of probability
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append({"intent": classes[r[0]], "probability": str(r[1])})
return return_listAfter predicting the class, we will get a random response from the list of intents.
def getResponse(ints, intents_json):
tag = ints[0]['intent']
list_of_intents = intents_json['intents']
for i in list_of_intents:
if(i['tag']== tag):
result = random.choice(i['responses'])
break
return result
def chatbot_response(text):
ints = predict_class(text, model)
res = getResponse(ints, intents)
return resWe will now create a graphical interface. Let’s use the Tkinter library sent by tons of useful GUI libraries. We’ll take an input message from the user and use the help functions we’ve created to get feedback on the board and display it in the GUI. Here is the complete source code for the GUI.
#Creating GUI with tkinter
import tkinter
from tkinter import *
def send():
msg = EntryBox.get("1.0",'end-1c').strip()
EntryBox.delete("0.0",END)
if msg != '':
ChatLog.config(state=NORMAL)
ChatLog.insert(END, "You: " + msg + '\n\n')
ChatLog.config(foreground="#442265", font=("Verdana", 12 ))
res = chatbot_response(msg)
ChatLog.insert(END, "Bot: " + res + '\n\n')
ChatLog.config(state=DISABLED)
ChatLog.yview(END)
base = Tk()
base.title("Hello")
base.geometry("400x500")
base.resizable(width=FALSE, height=FALSE)
#Create Chat window
ChatLog = Text(base, bd=0, bg="white", height="8", width="50", font="Arial",)
ChatLog.config(state=DISABLED)
#Bind scrollbar to Chat window
scrollbar = Scrollbar(base, command=ChatLog.yview, cursor="heart")
ChatLog['yscrollcommand'] = scrollbar.set
#Create Button to send message
SendButton = Button(base, font=("Verdana",12,'bold'), text="Send", width="12", height=5,
bd=0, bg="#32de97", activebackground="#3c9d9b",fg='#ffffff',
command= send )
#Create the box to enter message
EntryBox = Text(base, bd=0, bg="white",width="29", height="5", font="Arial")
#EntryBox.bind("<Return>", send)
#Place all components on the screen
scrollbar.place(x=376,y=6, height=386)
ChatLog.place(x=6,y=6, height=386, width=370)
EntryBox.place(x=128, y=401, height=90, width=265)
SendButton.place(x=6, y=401, height=90)
base.mainloop()5) Results and outputs
To run the chatbot, we have two main files; train_chatbot.py and chatapp.py.
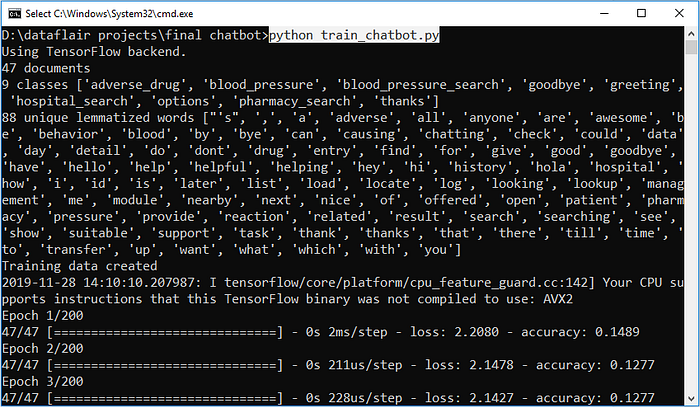
First, we train the model using the command in the terminal:
python train_chatbot.pyIf we don’t see any error during training, we have successfully created the model. Then to run the app, we run the second file.
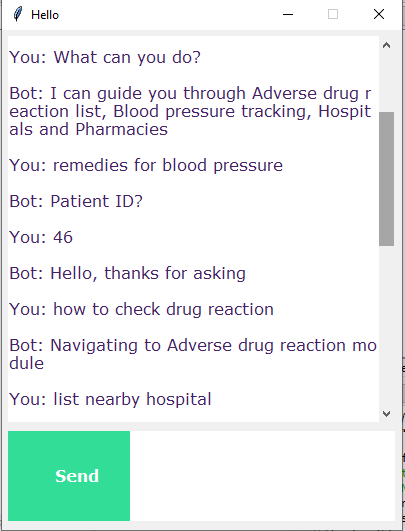
python chatgui.pyThe program will open up a GUI window within a few seconds. With the GUI you can easily chat with the bot.
6) Conclusion and future scope
The data collected in the chatbot survey justifies the recent growth and demand for companies looking to integrate the chatbot. It was determined that the interviews work at a very high level and provide reliable and prompt responses to users compared to traditional methods. The average time spent interacting with a chatbot is very low as it provides an effective way for users to manage their banking. Low communication time shows high understanding and levels of speech recognition, provided by the acceptance of chat channels thus allowing users to interact freely with the chatbot to meet the needs of modern life. Chatbot has been shown to meet the need of users who want quick access and access information and services.
7) References
- http://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43274.pdf
- https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
- [Sutskever, Vinyals, and Le 2014] Sutskever, I.; Vinyals, O.; and Le, Q. V. 2014. Sequence to sequence learning with neural networks. CoRR abs/1409.3215.
- deeplearning.ai Coursera